HOS 2.1 Instalación de Ceph con personalización de la red (8 de 8)
2016-01-23

Machine-translated from English. Read the English original
¡La verdad, la verdad completa…!
Aquí están los errores que encontré durante esta instalación.
Error – 1
Al ejecutar el procesador de configuración, este aceptará una clave de cifrado corta y no advertirá ni generará un error hasta el final de la ejecución.

Vuelvo a ejecutar el procesador de configuración y utilizo una contraseña de cifrado más fuerte: ‘H3lionhelion!’
Y así pasamos a la siguiente configuración que necesita ser depurada…
Error – 2
cd ~/helion/hos/ansible
ansible-playbook -i hosts/localhost config-processor-run.yml
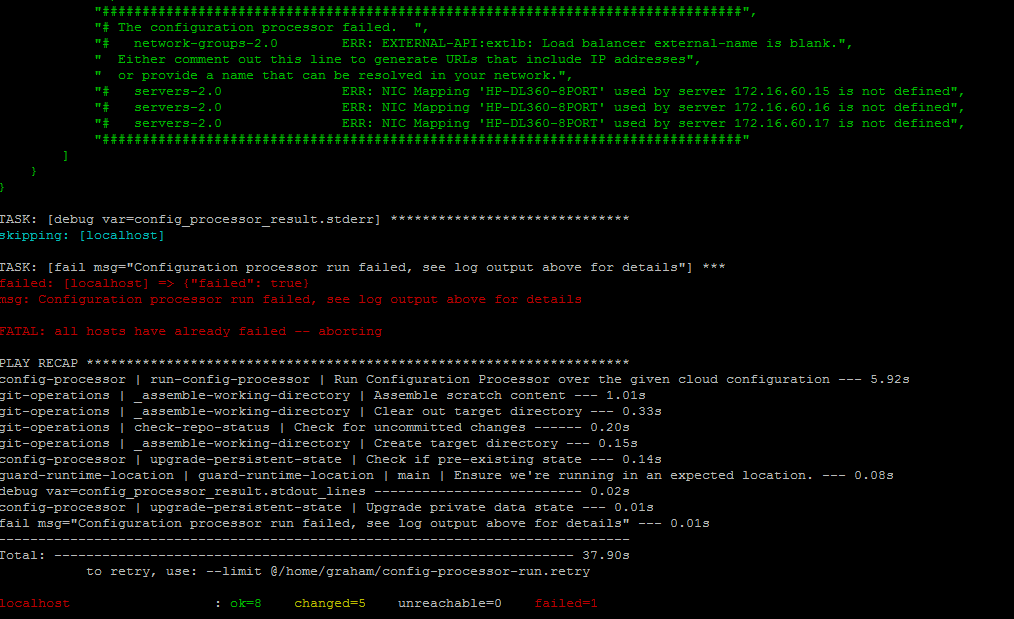
Si observamos el archivo network_groups.yml, puedo ver que olvidé modificar esta sección
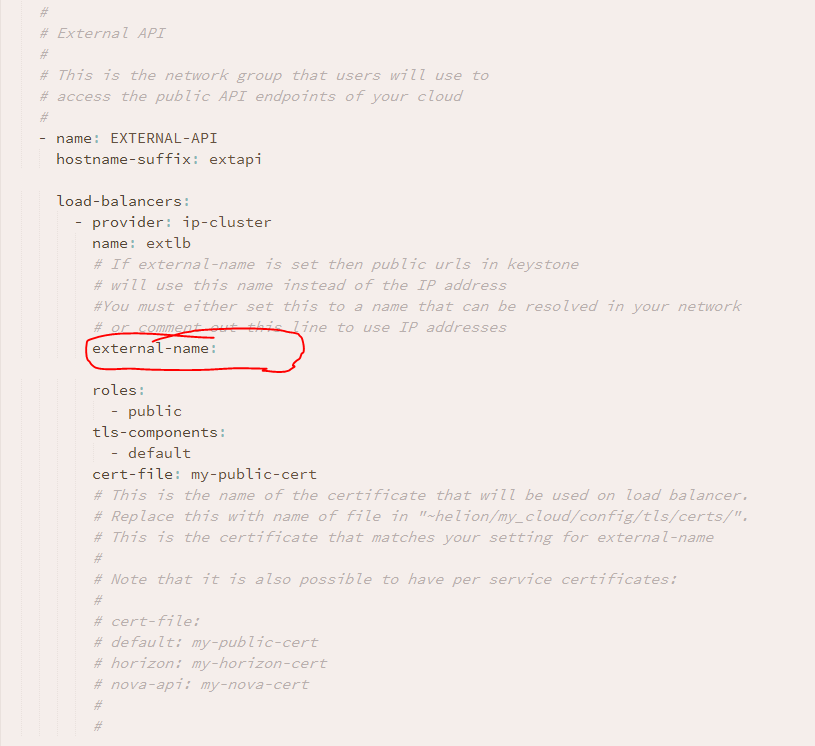
Añadí ‘hos2.allthingscloud.eu’ como el nombre externo

Error – 3
También se queja sobre los perfiles nic_mapping asignados en el archivo servers.yml.
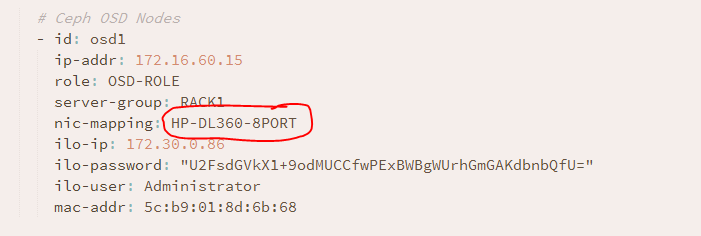
Este perfil faltaba en el archivo nic_mappings.
Añadí el perfil correcto, HP-DL360-8PORT, al archivo nic_mappings.

Ahora necesitamos volver a confirmar todos estos cambios en el repositorio y empezar de nuevo.
cd ~/helion/hos/ansible
git add -A
git commit -m "Fixed initial configuration errors"
Error – 4
cd ~/scratch/ansible/next/hos/ansible
ansible-playbook -i hosts/verb_hosts wipe_disks.yml
Tengo el siguiente ERROR al intentar borrar los discos

Esto se debe a que cifré el contenido sensible; para superar esto, necesito proporcionar --ask-vault-pass como parte de la línea de comandos
ansible-playbook -i hosts/verb_hosts wipe_disks.yml --ask-vault-pass
Error – 5
Y justo cuando creo que casi he terminado, obtengo otro fallo como el siguiente:
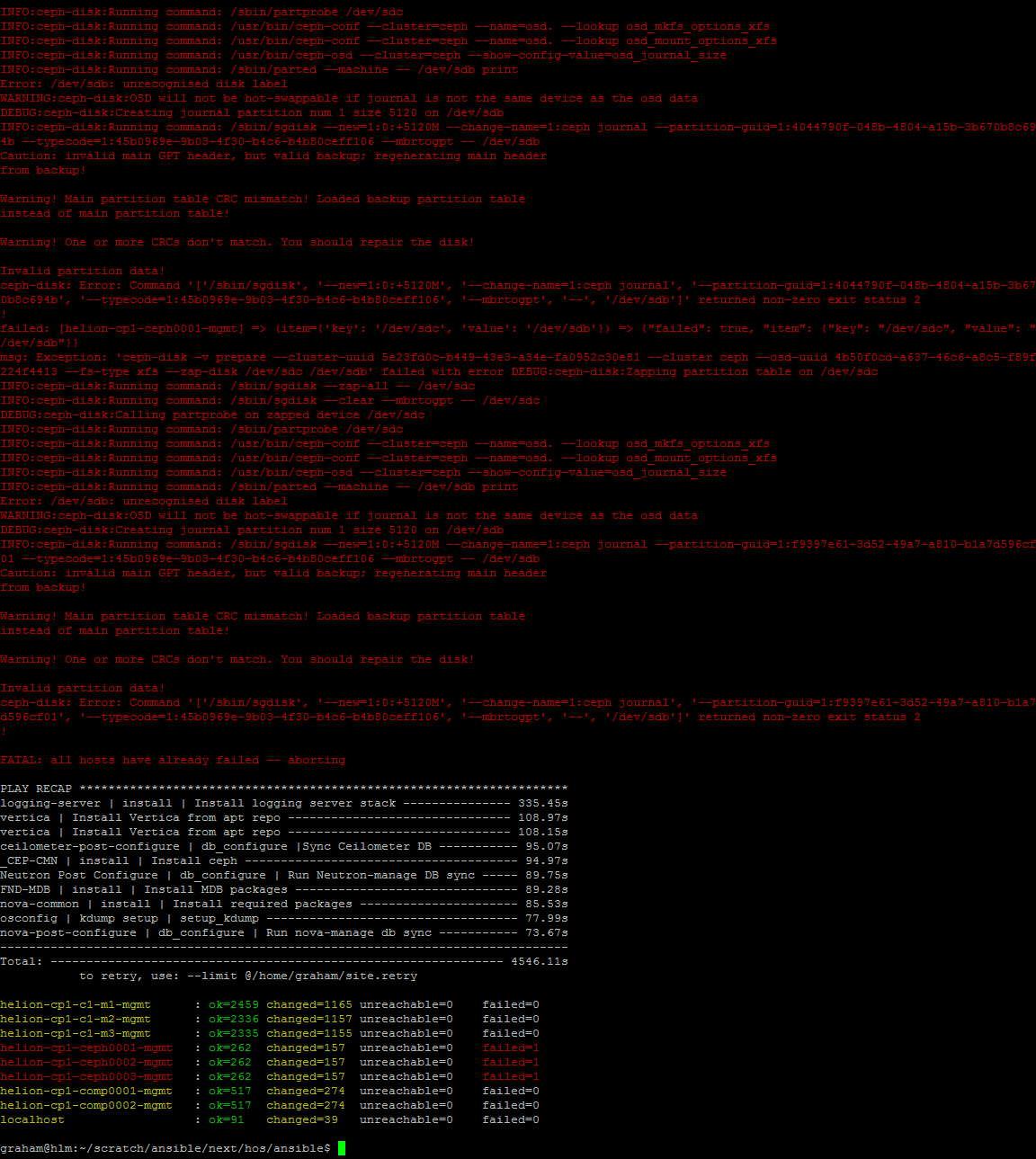
Muchas quejas en ~/.ansible/ansible.log sobre particiones de disco corruptas; intenté “limpiarlas manualmente” utilizando el siguiente script:
clear_host() {
ssh $1 << EOF
echo onhost connected
sudo /bin/dd if=/dev/zero of=/dev/sdb bs=512 count=2
sudo /bin/dd if=/dev/zero of=/dev/sdc bs=512 count=2
sudo /bin/dd if=/dev/zero of=/dev/sdd bs=512 count=2
sudo /bin/dd if=/dev/zero of=/dev/sde bs=512 count=2
sudo /bin/dd if=/dev/zero of=/dev/sdf bs=512 count=2
sudo /bin/dd if=/dev/zero of=/dev/sdg bs=512 count=2
sudo /bin/dd if=/dev/zero of=/dev/sdh bs=512 count=2
sync
EOF
}
export -f clear_host
seq 15 17 | while read i; do
clear_host 172.16.60.$i
done
Esto tampoco hizo diferencia. Obtengo el mismo error de partición.
Mi próximo intento de solución será iniciar sesión en el controlador RAID de cada servidor Ceph y eliminar y volver a crear las unidades que no son del sistema operativo.
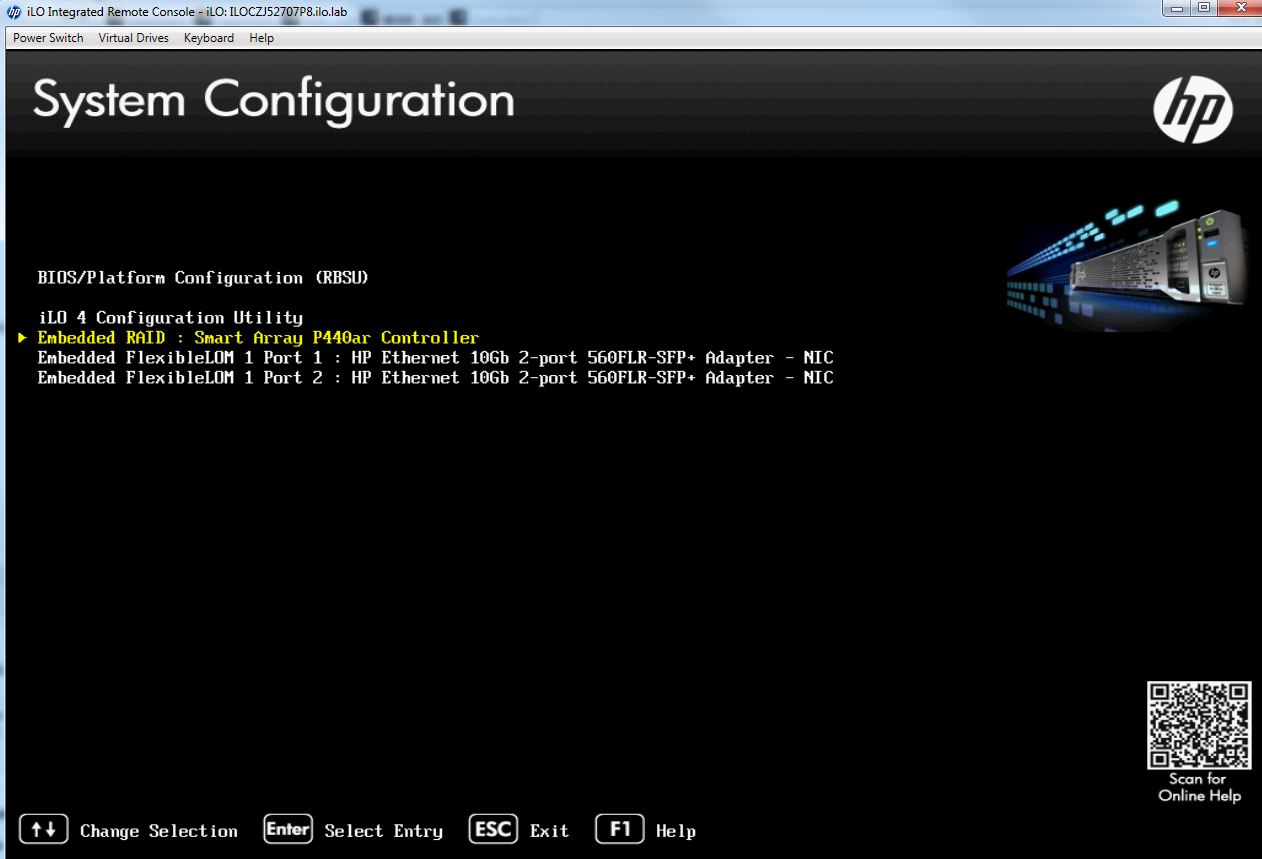
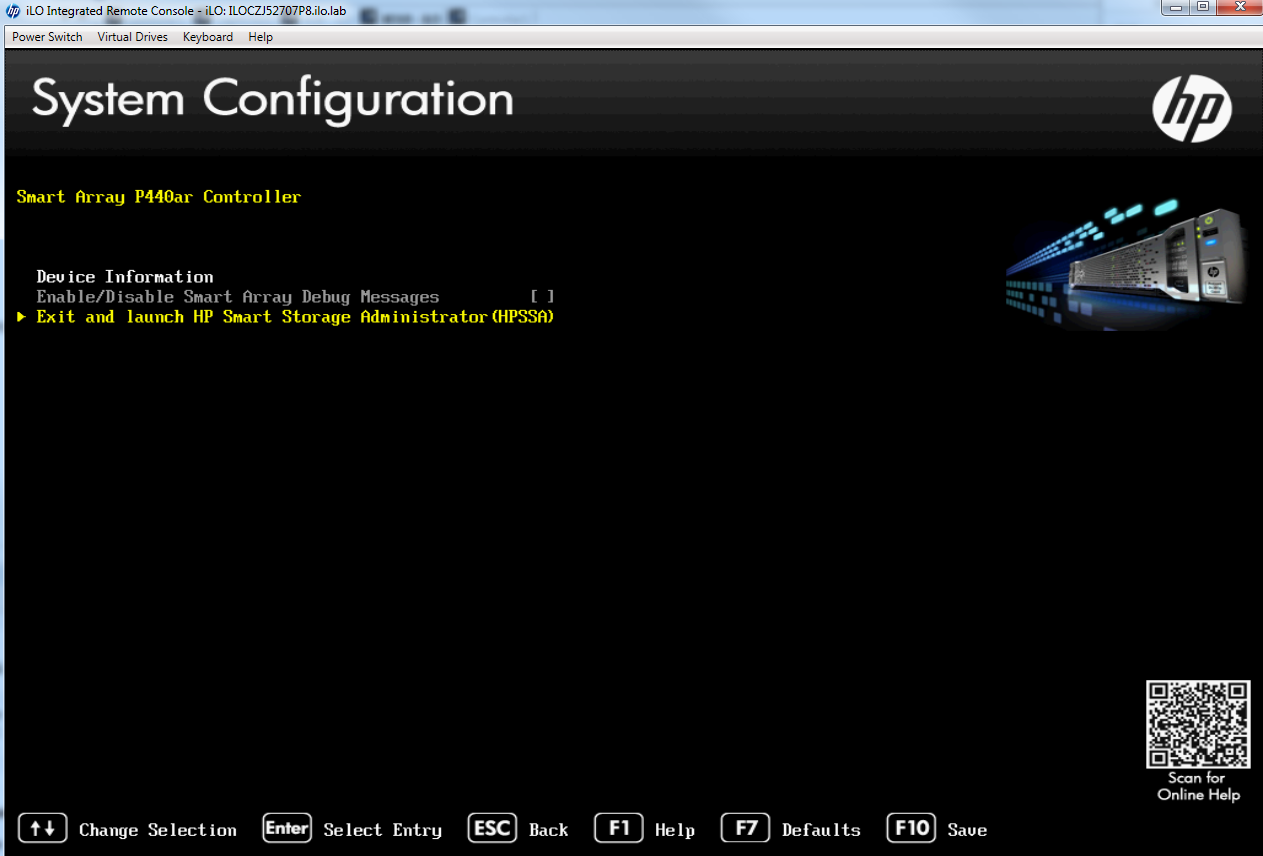
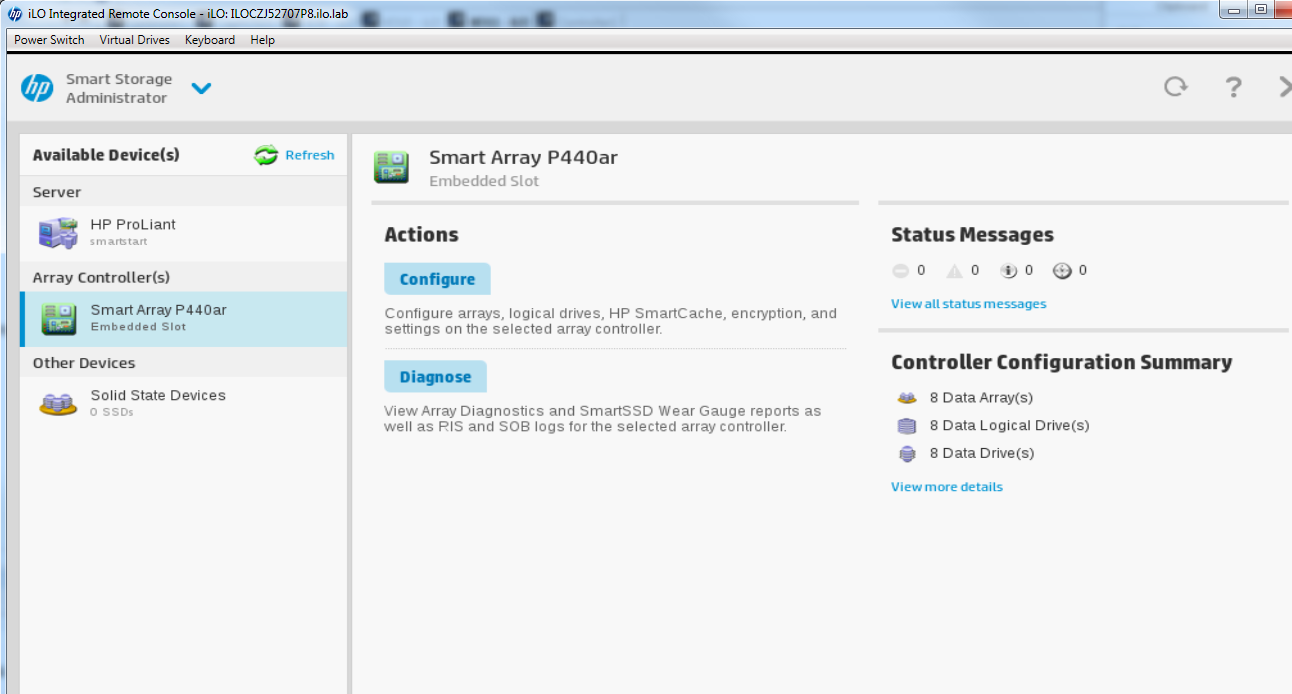
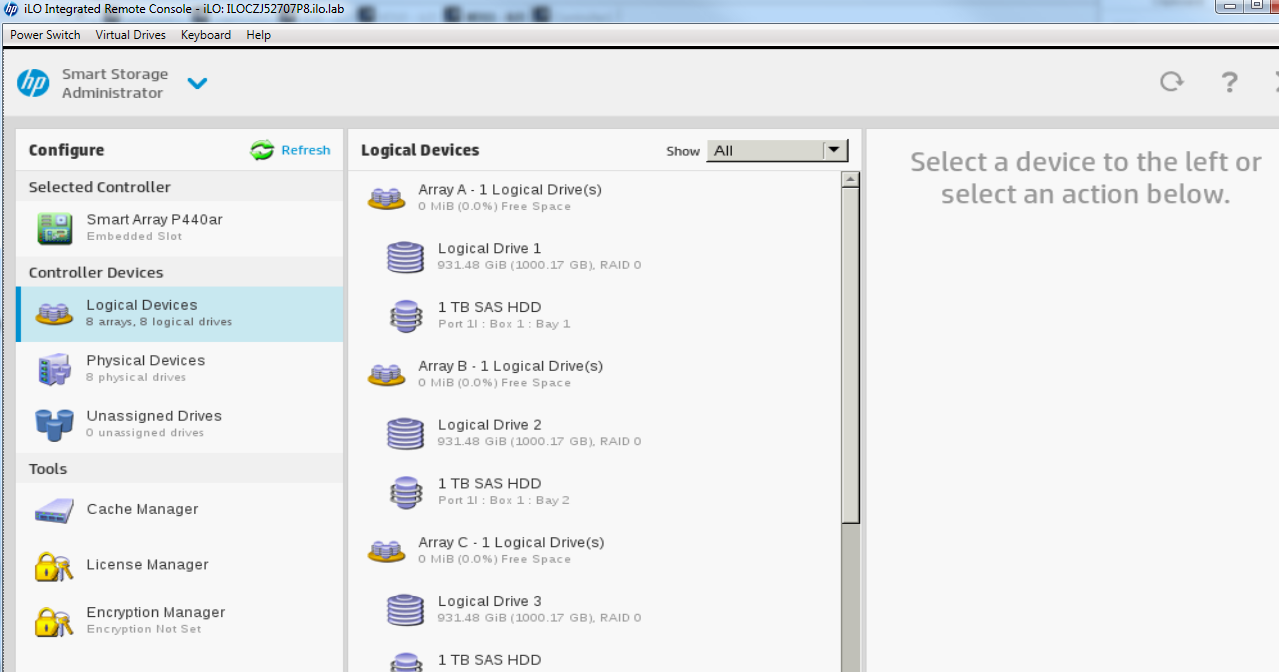
Ahora eliminaré todas las matrices EXCEPTO la Matriz A – la unidad del sistema operativo
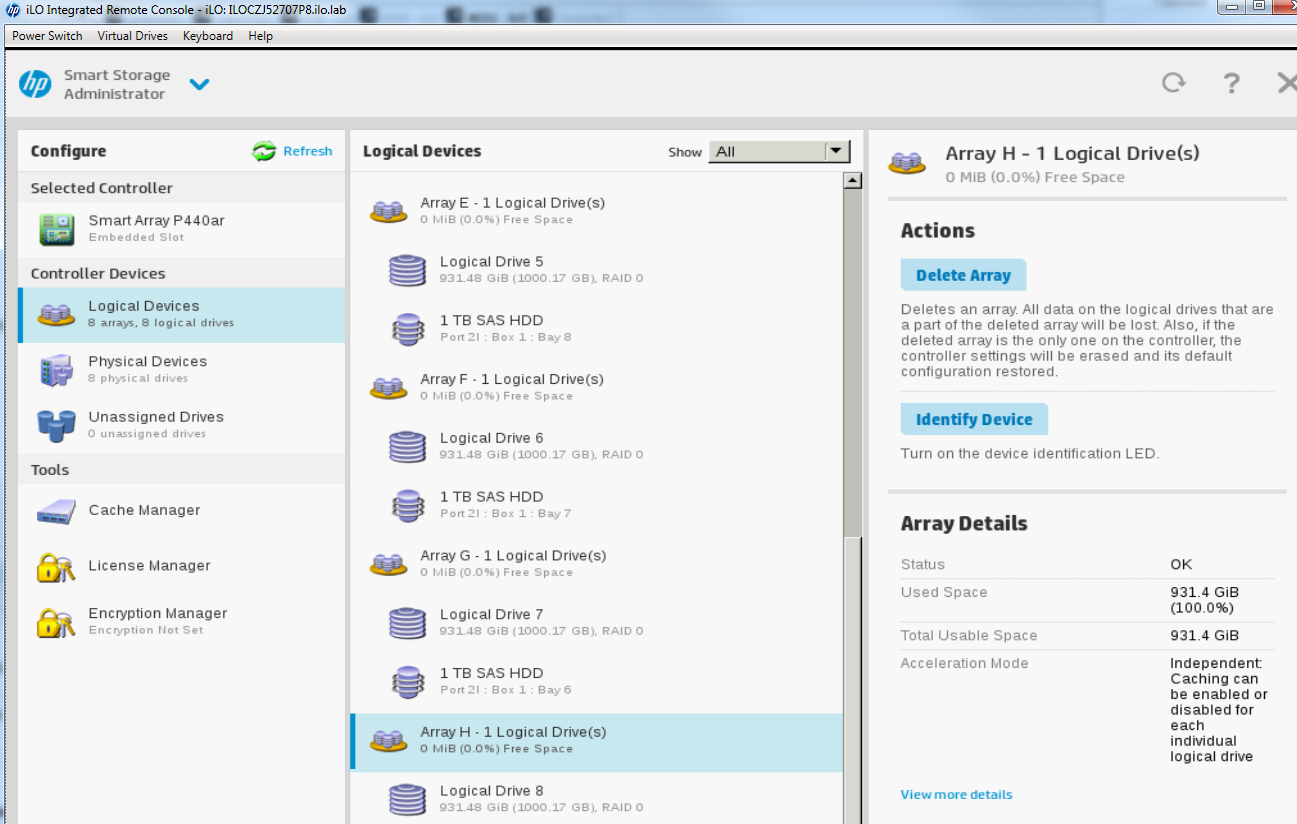
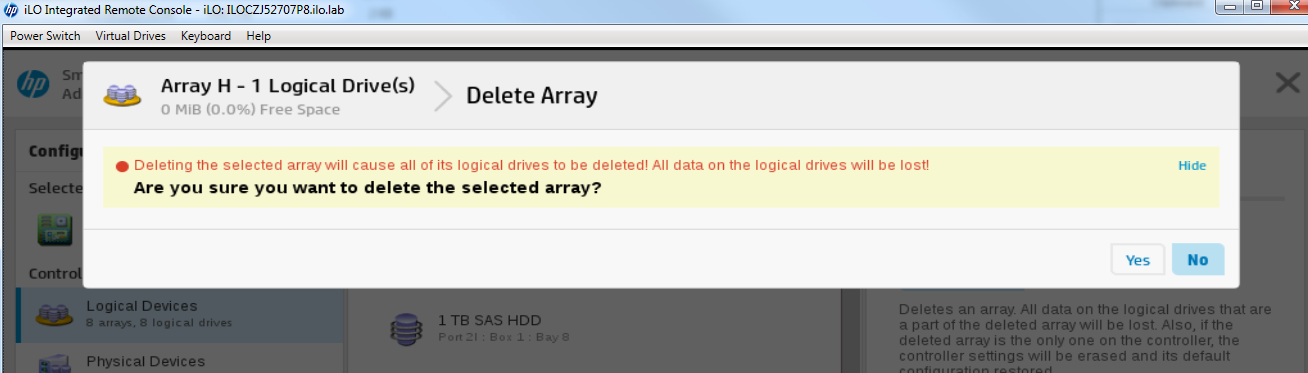
Repite esto para las matrices B – G y deberías terminar con algo como esto:
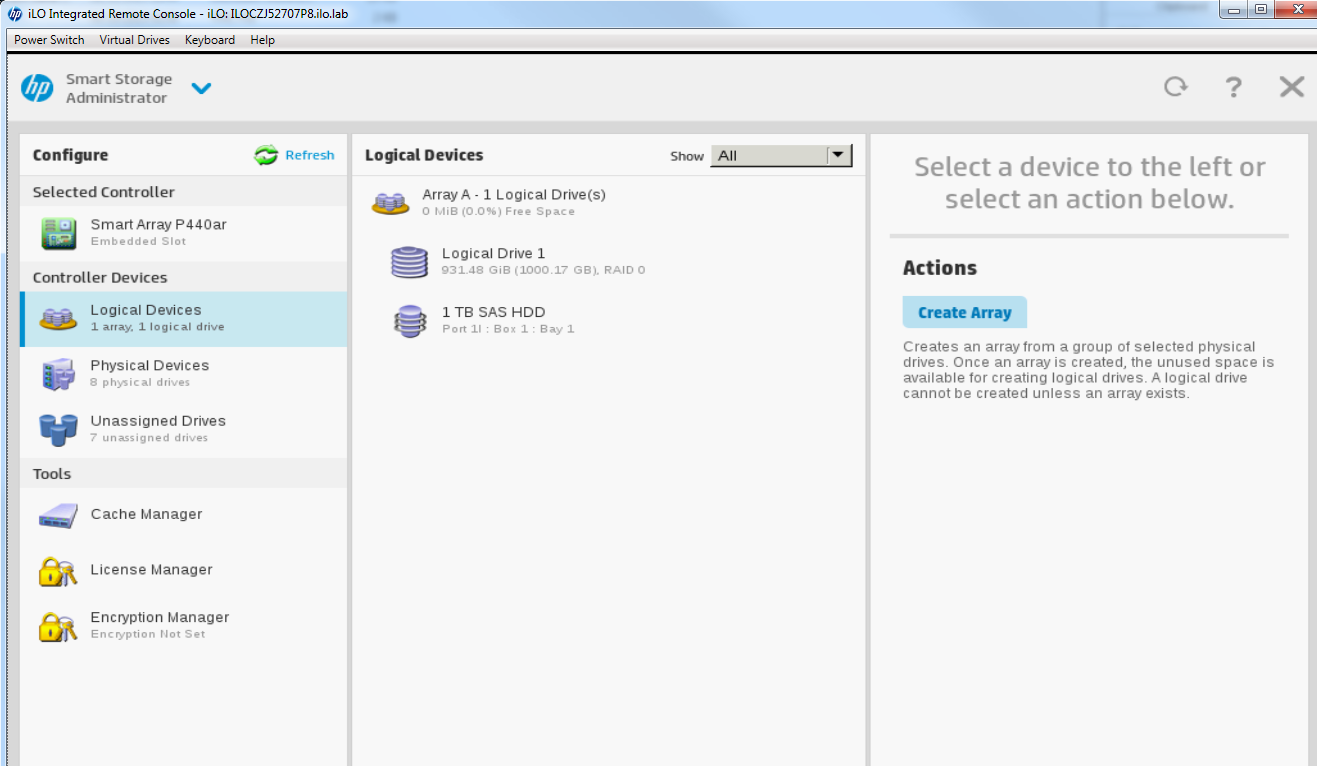
Ahora reconstruye todas las matrices de discos RAID0
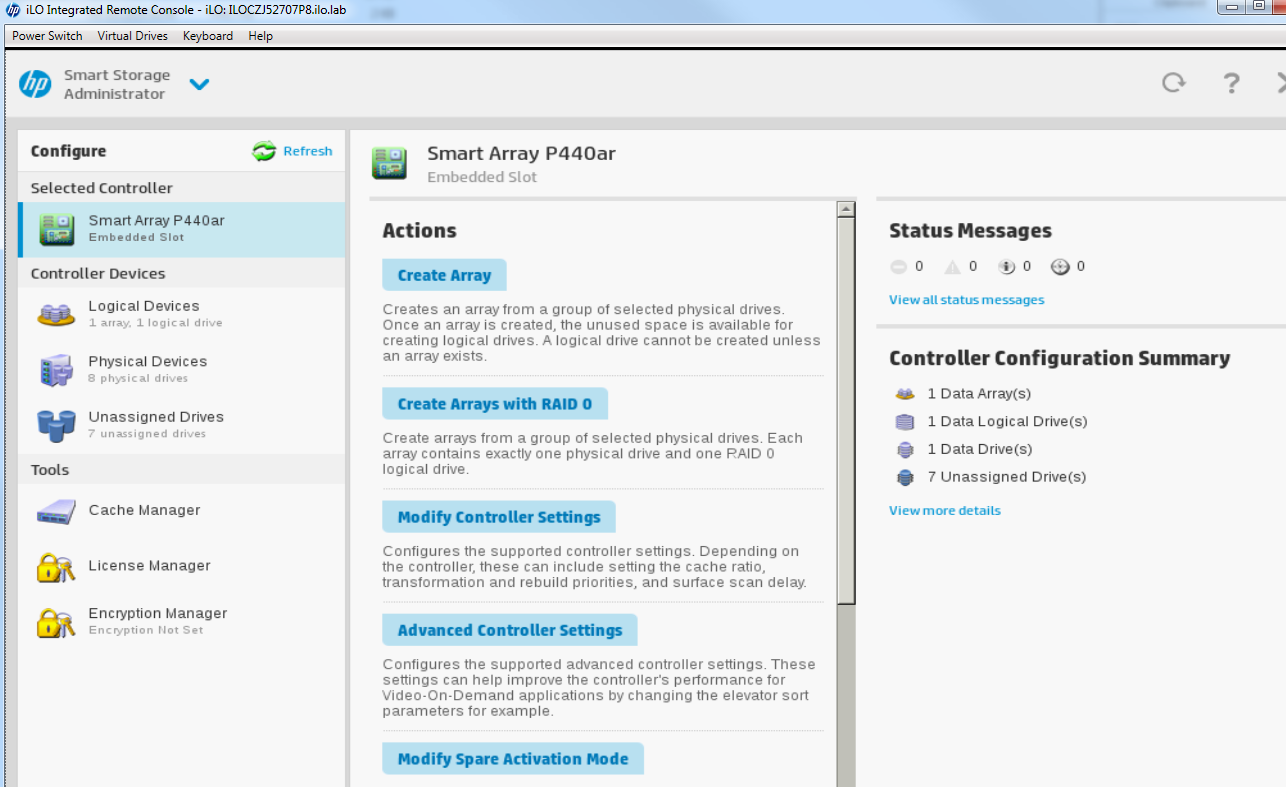
Selecciona la opción “Create Arrays with RAID 0”
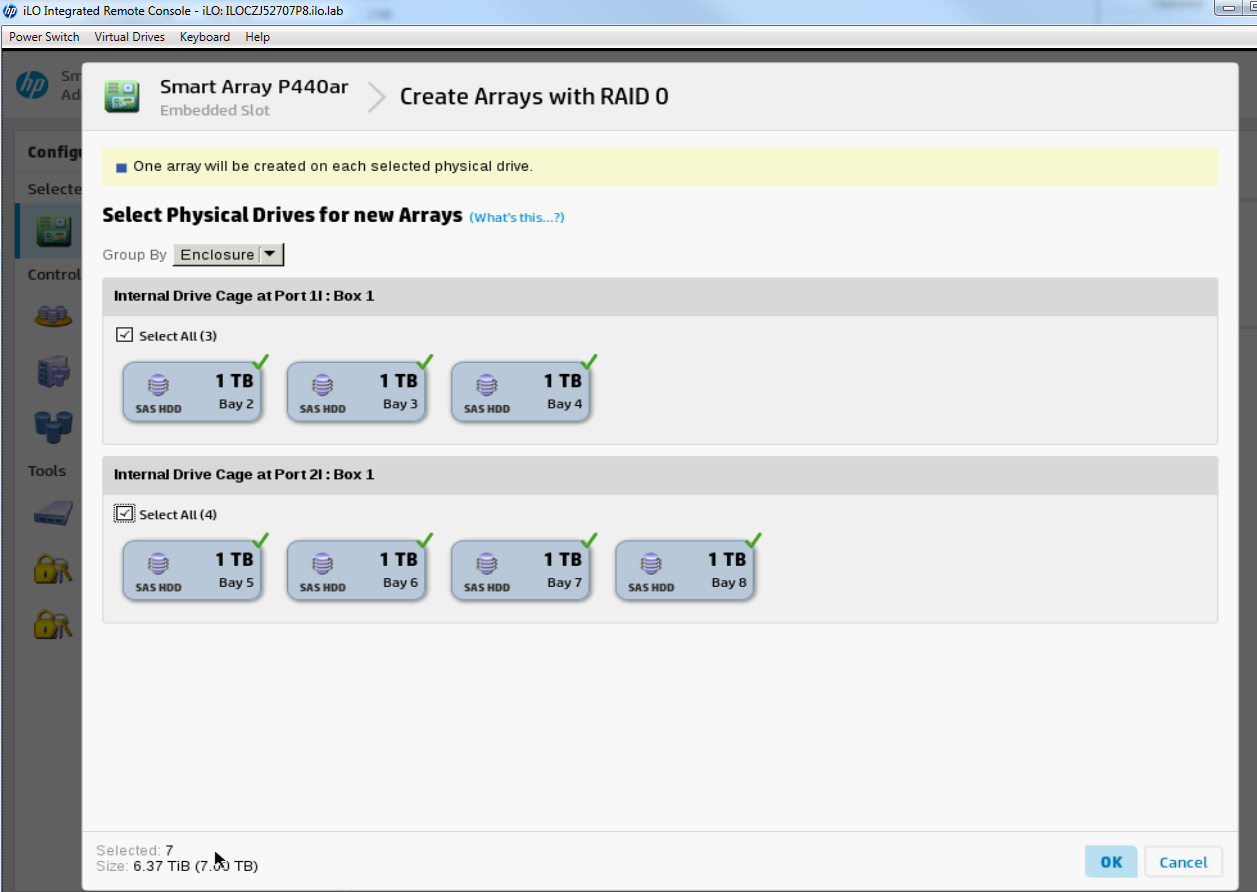
Selecciona OK
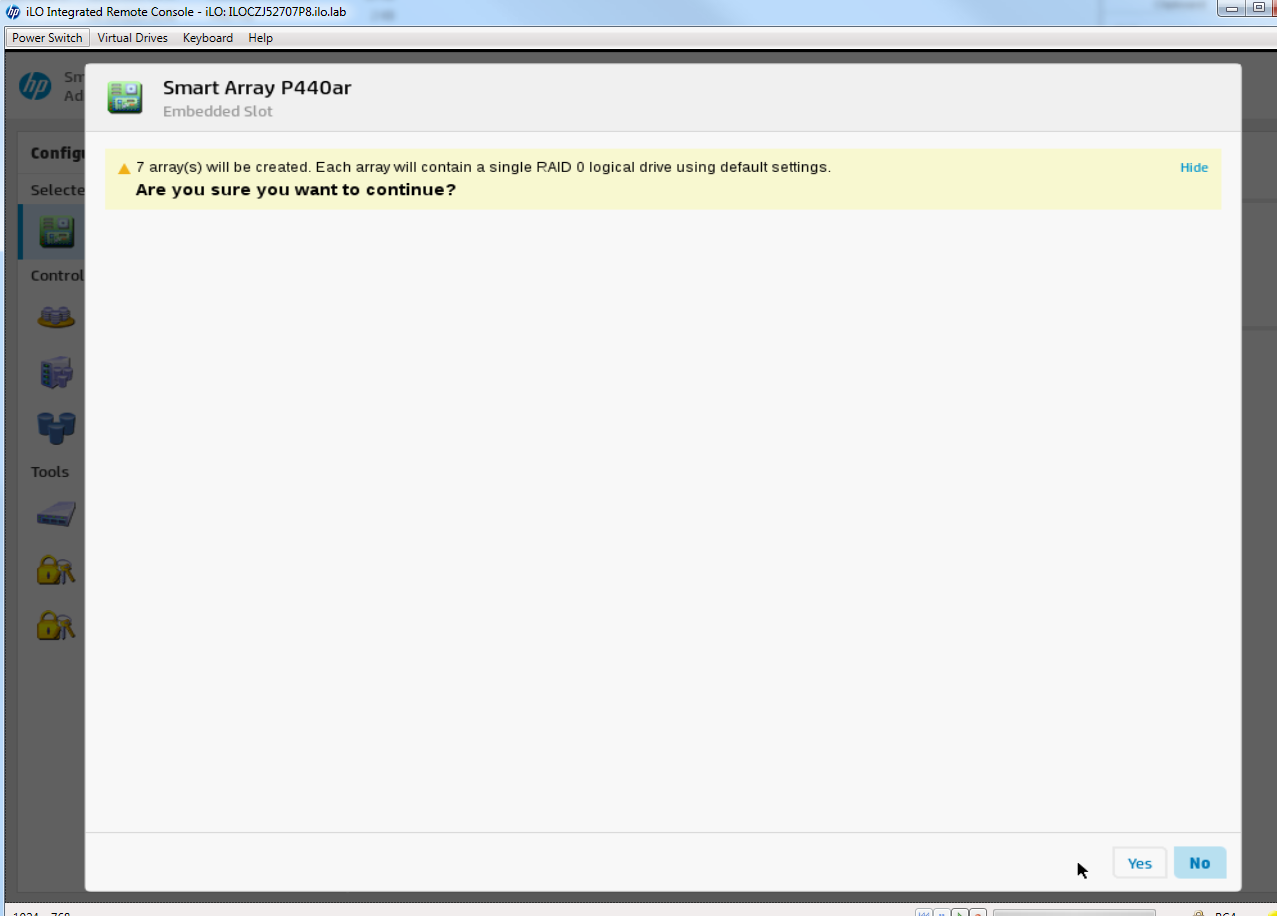
Repite este proceso en los otros 2 nodos Ceph y luego podemos volver a lanzar el despliegue de nuevo
ansible-playbook -i hosts/verb_hosts site.yml --ask-vault-pass --limit @/home/graham/site.retry
Una vez más tenemos exactamente el mismo fallo; es hora de buscar errores conocidos…
Sí, este es un error conocido: la funcionalidad wipe_disk no siempre funciona correctamente.
Es necesario iniciar sesión en cada nodo y ejecutar el siguiente comando contra cada unidad de journal y OSD:
/sbin/sgdisk --zap-all -- /dev/sd[b-h]
o utiliza el siguiente script:
clear_host() {
ssh $1 << EOF
echo onhost connected
sudo /sbin/sgdisk --zap-all -- /dev/sdb
sudo /sbin/sgdisk --zap-all -- /dev/sdc
sudo /sbin/sgdisk --zap-all -- /dev/sdd
sudo /sbin/sgdisk --zap-all -- /dev/sde
sudo /sbin/sgdisk --zap-all -- /dev/sdf
sudo /sbin/sgdisk --zap-all -- /dev/sdg
sudo /sbin/sgdisk --zap-all -- /dev/sdh
sync
EOF
}
export -f clear_host
seq 15 17 | while read i; do
clear_host 172.16.60.$i
done
Error – 6
Y ahora continuamos desde donde lo dejamos –
ansible-playbook -i hosts/verb_hosts site.yml --ask-vault-pass --limit @/home/graham/site.retry
Esto me lleva al siguiente desafío –
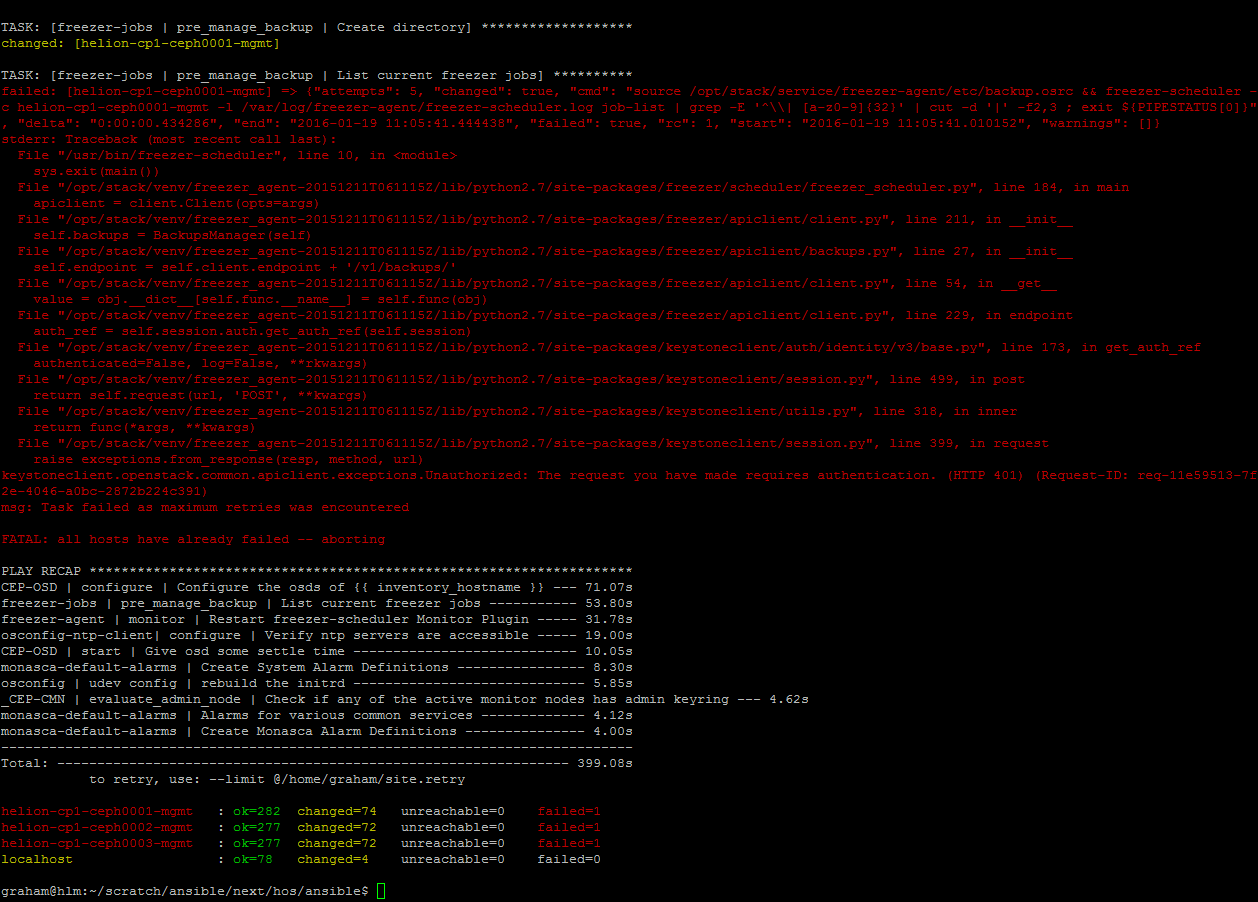
Como puedes ver, esto se queja sobre la autenticación. Lo que no puedes ver es que han pasado más de 12 horas desde que me volví a unir a la sesión de pantalla fallida original. Al añadir --limit @/home/graham/site.retry, intenta continuar desde donde falló. Sin embargo, parece que algunos tokens de autenticación pueden haber expirado posteriormente.
Vuelve a lanzar la instalación sin la opción --limit @/home/graham/site.retry.
ansible-playbook -i hosts/verb_hosts site.yml --ask-vault-pass
Originally published on allthingscloud.eu (2016-01-23).